Academics — and others — increasingly write software. And we increasingly host it on GitHub. How can we uncover the impact our software has made, learn from it, and communicate this to people who evaluate our work?

GitHub itself gets us off to a great start. GitHub users can “star” repositories they like, and GitHub displays how many people have forked a given software project — started a new project based on the code. Both are valuable metrics of interest, and great places to start qualitatively exploring who is interested in the project and what they’ve used it for.
What about impact beyond GitHub? GitHub repositories are discussed on Twitter and Facebook. For example, the GitHub link to the popular jquery library has been tweeted 556 times and liked on Facebook 24 times (and received 18k stars and almost 3k forks).
Is that a lot? Yes! It is one of the runaway successes on GitHub.
How much attention does an average GitHub project receive? We want to know, to give reference points for the impact numbers we report. Archive.org to the rescue! Archive.org posted a list of all GitHub repositories active in December 2012. We just wanted a random sample of these, so we wrote some quick code to pull random repos from this list, grouped by year the repo was created on GitHub.
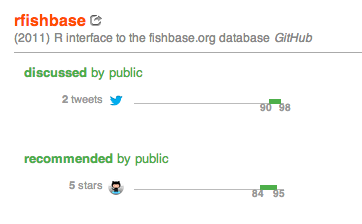
Here is our reference set of 100 random GitHub repositories created in 2011. Based on this, we’ve calculated that receiving 3 stars puts you in the top 20% of all GitHub repos created in 2011, and 7 stars puts you in the top 10%. Only a few of the 100 repositories were tweeted, so getting a tweet puts you in the top 15% of repositories.
You can see this reference set in action on this example, rfishbase, a GitHub repository by rOpenSci that provides an R interface to the fishbase.org database:
So at this point we’ve got recognition within GitHub and social media mentions, but what about contribution to the academic literature? Have other people used the software in research?
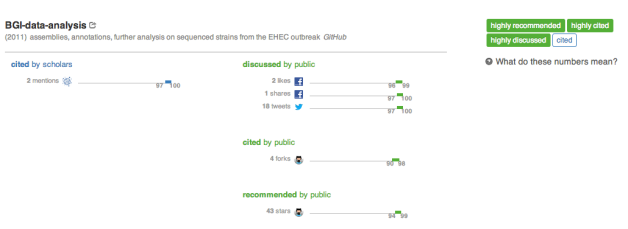
Software use has been frustratingly hard to track for academic software developers, because there are poor standards and norms for citing software as a standalone product in reference lists, and citation databases rarely index these citations even when they exist. Luckily, publishers and others are beginning to build interfaces that let us query for URLs mentioned within full text of research papers… all of a sudden, we can discover attribution links to software packages that are hidden in not only in reference lists, but also methods sections and acknowledgements! For example, the GitHub url for a crowdsourced repo on an E Coli outbreak has been mentioned in the full text of two PLOS papers, as discovered on ImpactStory:
There is still a lot of work for us all to do. How can we tell the difference between 10 labmates starring a software repo and 10 unknown admirers? How can we pull in second-order impact, to understand how important the software has been to the research paper, and how impactful the research paper was?
Early days, but we are on the way. Type in your github username and see what we find!