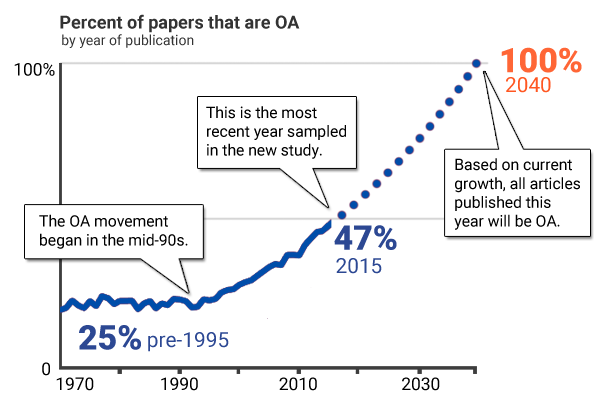
Thanks to 20 years of OA innovation and advocacy, today you can legally access around half the recent research literature for free. However, in practice, much of this free literature is not as open as we’d like it to be, because it’s hard for readers to find the OA version.
OA lives on repositories and publisher websites. But very few people visit these sources directly to find a given article. Instead, people rely on the search tools that are already part of their existing workflows. Historically, these haven’t done a great job surfacing OA resources. Google, for instance, often fails to index OA versions, in addition to indexing content of dubious provenance. OA aggregators like BASE, CORE, and OpenAIRE aim to solve this by emphasizing OA coverage, but they require researchers to add a second or third search step to their existing workflows–something researchers have been reluctant to do.
So in addition to the well-known access problem, we also have a discovery problem. On the one there’s a healthy, efficient OA infrastructure in journals and repositories. On the other we have millions of individual readers doing their own thing. We need to connect these. We need to cover this last mile between the infrastructure and the individual user, and we need to make that connection easy and seamless and ubiquitous. Until we do, OA is writing a check it can’t fully cash.
But the news is good: over the last year, several efforts are emerging to cover that last mile. Our contribution was Unpaywall: an extension that shows a green tab in your browser on articles where there’s an OA version available. Unpaywall has enjoyed lots of success, adding over 100,000 active users in under than a year. Moreover, the backend database of Unpaywall (formerly called oaDOI) can be integrated into any number of existing tools, making it easier to spread OA content all over the place. For instance, we’re already seeing over a million uses every day from library link resolvers.
Our most recent integration takes this to a new level, and we’re so excited about it: thanks to a new partnership between Impactstory and Clarivate Analytics, data from Impactstory’s Unpaywall database is now live in the Web of Science, making it the first editorially-curated and publisher-neutral resource to implement this technology. Web of Science has been able to use Unpaywall data to discover and link to millions more OA records amongst their existing content. This enables millions of Web of Science users around the world to link straight from their search results to a trusted, legal, peer-reviewed OA version—and they can also filter search results by the different versions of OA.
This is a big deal because article and indexing (A&I) systems like Web of Science are currently the most important way researchers access literature. And though it’s by no means the only A&I system out there, Web of Science is the most respected and most prevalent. Every month, millions of users access literature through Web of Science—and now, each and every one of them will see more OA options for articles they might not otherwise discover, right alongside subscribed content. Every day. What a huge change from the days we had to convince folks that OA was legitimate at all! It’s a new era.
A new era: that’s not just a hyperbolic phrase. We think this year marks the turning of a new moment in the OA narrative. We’re moving out of the author-focused, advocacy-focused initial phase, and into a more mature era of ubiquitous Open Access, characterized by deep integration of OA into researcher workflows and value-add services built on top of the immense OA corpus. This is the era of user-focused OA.
As OA becomes the default state for published research, tools that centralize, mine, index, search, organize, and extract knowledge from papers suddenly become massively more powerful. Integrations between Unpaywall and commercial services aren’t generating this new era, but they are one of the hallmarks of it. We’re not making new OA, but rather starting to leverage the massive OA corpus now available. In the last year, many others have begun to do this as well. Many, many more will follow
For years, we in the OA advocate community have been arguing that a critical mass of OA would not just improve scholarly communication, it would transform it. This is finally beginning to happen, and we think this partnership with Web of Science is an early part of that transformation. Now, a subscription to Web of Science—something most academic libraries globally already have—is also a subscription to a database of millions of free-to-read OA articles.
We’ve never been more excited about the future of OA–or more thankful for all the work the OA community as a whole has done to get here. And we can’t wait to keep working together with the community to help make the vision of ubiquitous open access a reality.